Knowledge Base Engineering Guide — Knowledge Modeling and Storage
Preface: The initial wave of GenAI investments focused heavily on rapid prototyping and experimentation. Many organizations found their early solutions quickly outdated as the technology evolved, leading to a shift toward more strategic, outcome-driven approaches.
A well-engineered knowledge base serves as the foundation for semantic search, recommendations, and enterprise intelligence. It becomes more valuable over time as it captures your organization’s unique business processes and domain expertise, while remaining flexible enough to leverage advancing AI capabilities.
We will explore the key components of knowledge base engineering in a series of blogs. This blog focuses on Knowledge Modeling and Storage Infrastructure. Subscribe my channel to get my latest articles on this topic.
Knowledge Modeling
Knowledge modeling is often misunderstood in the era of LLMs. While LLMs have dramatically improved our ability to process unstructured data, effective knowledge engineering still benefits from thoughtful structure — much like how database design remains crucial despite having powerful query engines.
Inherent Structure & Additional Modeling
The reality is that most “unstructured” data already contains valuable implicit structure. PDFs carry rich layout information through headers, sections, and formatting. PowerPoint presentations organize content hierarchically across slides, with titles and bullet points providing natural segmentation. Web pages embed semantic structure through HTML tags and metadata. In the operational realm, SaaS application logs and system metrics come with built-in structure — timestamps, severity levels, service identifiers, and JSON-formatted event data. Even seemingly unstructured data like meeting recordings contain natural structure through speaker turns and temporal segments.
The first step in knowledge modeling is effectively parsing and chunking this inherent structure. Approaches such as semantic chunking respect natural content boundaries, maintain contextual coherence, and preserve hierarchical relationships. For example, a technical document might be chunked based on section boundaries rather than arbitrary character counts, ensuring that related concepts stay together.
However, basic parsing and chunking aren’t enough for sophisticated knowledge systems. Modern approaches focus on enriching content during the preprocessing phase — before it enters the retrieval system. Consider two cutting-edge approaches: Anthropic’s Contextual Retrieval and Lamini’s Memory RAG. Both enhance traditional RAG by improving how information is processed and structured before inference. Contextual Retrieval combines text chunks with their associated global context, showing that pure semantic search isn’t enough — business-specific context matters. Similarly, Memory RAG’s focus on embed-time compute demonstrates that preprocessing decisions directly impact retrieval quality (improve the accuracy of complicated sql generation from 20~40% to high 90%).
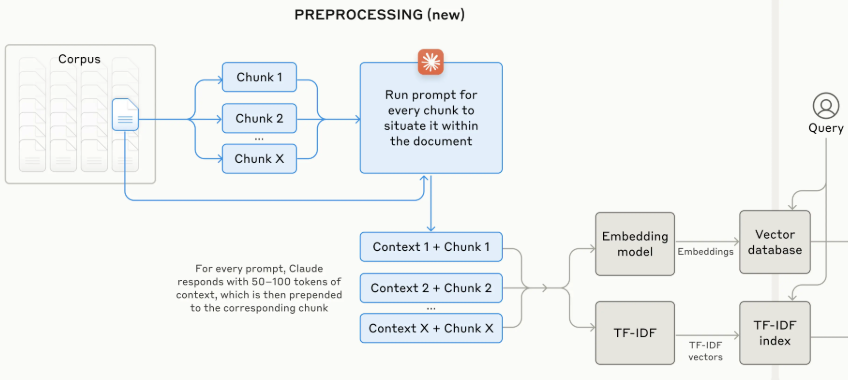 Contextual RAG (image created by Anthropic)
Contextual RAG (image created by Anthropic)
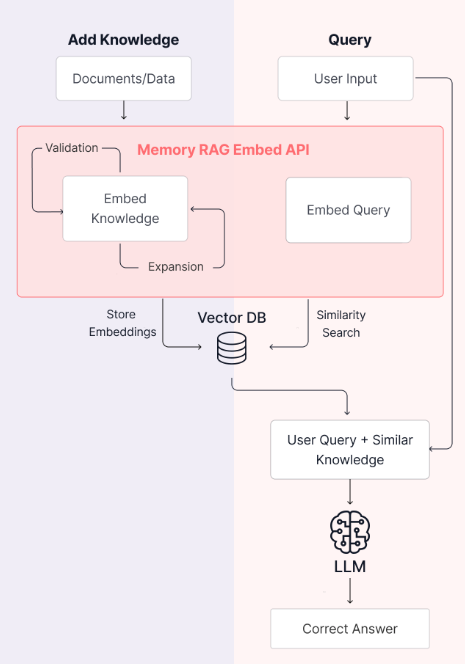 Memory RAG (image created by Lamini)
Memory RAG (image created by Lamini)
This evolution in knowledge modeling reflects a fundamental insight: while LLMs have transformed how we process unstructured data, the quality of knowledge representation still depends on how well we preserve and enhance inherent structure during the ingestion phase. The goal isn’t just to make content retrievable, but to maintain its original context and relationships while adding new layers of semantic understanding.
Balancing Structure and Flexibility
The evolution of knowledge modeling presents organizations with what initially appears to be a choice between control and adaptability. Traditional schema-based approaches offer precise control and efficient querying but require significant upfront design and ongoing maintenance. LLM-based approaches promise flexibility and easier maintenance but may sacrifice predictability and business-specific optimizations.
However, effective knowledge systems often need both structural rigor and semantic flexibility. Consider a technical support knowledge base: while LLMs can understand natural language queries and extract relevant information, the system still needs to maintain accurate product hierarchies, track issue categories, and enforce support workflow rules. Neither pure schema-based nor pure LLM-based approaches fully address these needs.
This requires hybrid approaches that combine traditional knowledge modeling with LLM capabilities:
- Explicit relationship modeling for critical business concepts
- Automated knowledge distillation for domain specialization
- Validation rules that enforce business logic
- Context-aware embeddings that capture domain-specific nuances
The GraphRAG approach exemplifies this hybrid model, using LLMs to construct and navigate graph structures dynamically while maintaining schema compliance. Such systems demonstrate how structured representations and flexible processing can complement rather than compete with each other, creating knowledge bases that are both robust and adaptable.
 An example GraphRAG pipeline (see explanations of each step here)
An example GraphRAG pipeline (see explanations of each step here)
The key insight is that LLMs haven’t replaced traditional knowledge modeling — they’ve transformed how we implement it. Apart from using rigid schemas, we now have flexible, context-aware structures that still maintain business-critical relationships and rules. The goal remains the same: ensuring information is organized in a way that serves specific business needs effectively.
Storage Infrastructure
The foundation of any knowledge base is its storage layer. Selecting the right database requires careful consideration of your use case requirements: query performance, data volume, search functionality, and scalability needs. Let’s explore the evolving landscape of knowledge base storage solutions.
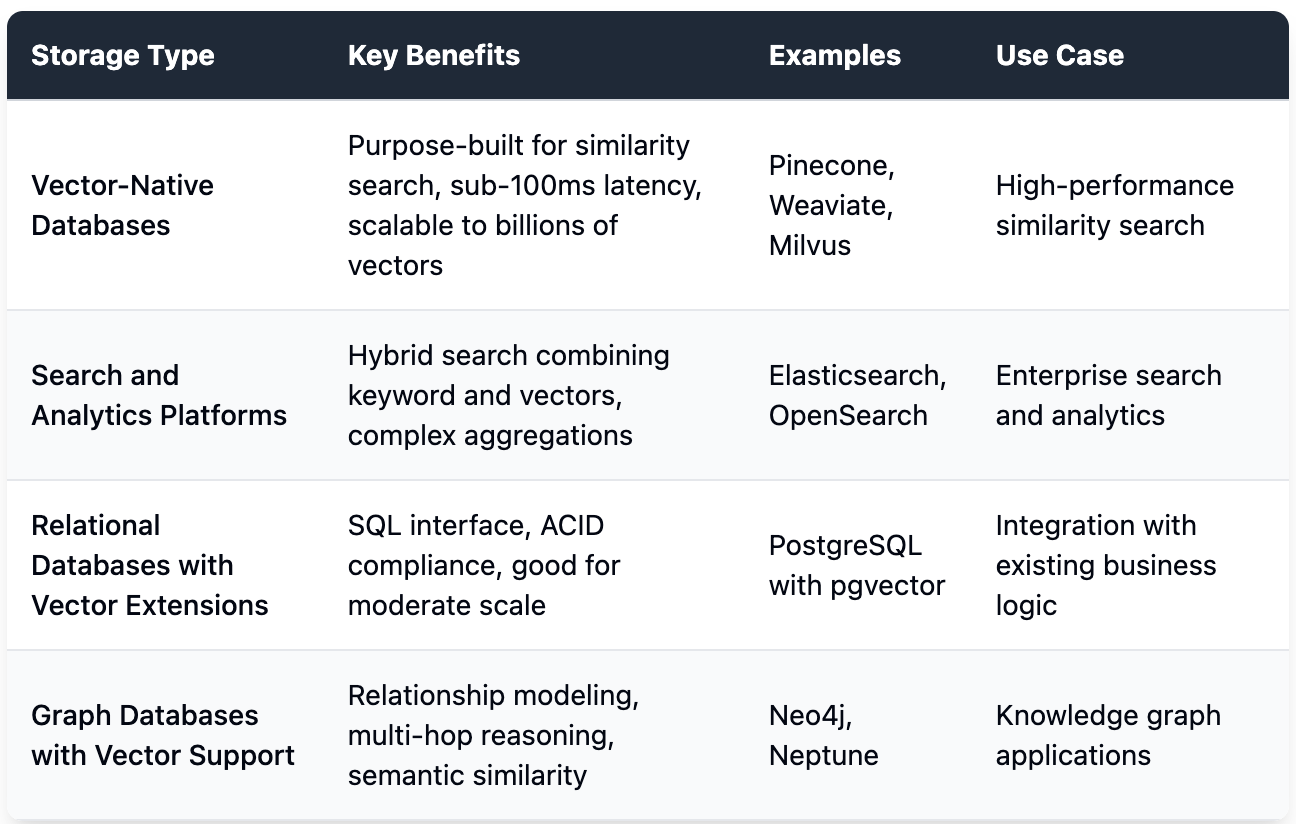 Storage Options for Knowledge Base Engineering (created by author)
Storage Options for Knowledge Base Engineering (created by author)
Vector-Native Databases
Modern vector databases like Pinecone, Weaviate, and Milvus are engineered specifically for high-performance similarity search. Unlike traditional databases with vector extensions, they commonly achieve consistent sub-100ms latency at scale through purpose-built architectures. Their indexing methods (HNSW, IVF) are deeply integrated into the core system, enabling efficient Approximate Nearest Neighbor (ANN) search over billions of vectors.
Consider a real-world example: A large e-commerce platform processing 1000 queries per second for visual product search. A vector native database excel through automated resource management — automatically allocating memory based on data size and query load, and maintaining vector indexes efficiently without manual intervention [1]. This is particularly valuable as your product catalog grows to millions of items, where traditional databases would require significant tuning and operational overhead.
Search and Analytics Platforms
Elasticsearch and OpenSearch have evolved beyond traditional keyword search to become powerful hybrid search platforms. Their strength lies in combining multiple search paradigms:
- BM25 (sparse vector) for keyword matching
- Dense vector search for semantic similarity
- Complex aggregations and analytics
These platforms shine in scenarios requiring flexible querying across unstructured and structured text. A technical documentation system, for instance, might leverage Elasticsearch’s hybrid search to match both exact technical terms and semantically similar concepts, while handling millions of documents with sub-second response times.
Relational Databases with Vector Extensions
PostgreSQL with pgvector represents a pragmatic approach for organizations with moderate-scale vector search needs. While it may not match the raw performance of vector-native databases especially on large-sized workloads, it offers several advantages:
- SQL interface
- ACID compliance (for safe updates and consistent retrieval)
- Cost-effective for small to medium datasets
- Seamless integration with existing data models
When your vector search needs to be deeply integrated with traditional business logic and the scale is moderate, the simplicity of having everything in the relational database often outweighs the pure performance benefits of a dedicated vector database.
Graph Databases with Vector Support
Neo4j, Neptune, and similar graph databases have added vector capabilities to enhance their relationship-modeling strengths. This combination is particularly powerful for:
- Knowledge graphs with semantic similarity
- Multi-hop reasoning
- Complex relationship queries with similarity search
Consider a research paper recommendation system: Graph databases can traverse citation networks while using vector similarity to identify thematically related papers, offering unique insights that pure vector search might miss.
Selection Framework
The choice of storage technology isn’t just about vector search performance — it’s about aligning with your specific knowledge management needs. Consider three key dimensions:
- Query patterns: What types of queries will dominate your workload?
- Data characteristics: Volume, velocity, and variety of your data
- Operational requirements: Latency, consistency, and scale expectations
Note that as knowledge bases grow in complexity, the line between different storage solutions continues to blur. Vector-native databases are adding support for structured data, while traditional databases and search platforms are enhancing their vector capabilities. The key is choosing a solution that matches your current needs while maintaining flexibility for future growth. When in doubt, start with your primary use case and most critical queries — let these guide your storage decision rather than trying to optimize for every possible scenario.
Conclusion
In this first article of our knowledge engineering series, we’ve explored two fundamental components: knowledge modeling & ingestion, and storage infrastructure. We’ve seen how modern knowledge engineering requires a nuanced understanding of both inherent data structure and additional modeling layers. The emergence of LLMs hasn’t eliminated the need for thoughtful knowledge modeling — instead, it has transformed how we approach it, leading to hybrid solutions that combine traditional structure with AI-powered flexibility.
We’ve also examined how the choice of storage infrastructure impacts the entire knowledge engineering pipeline, from vector databases optimized for semantic search to graph databases that preserve complex relationships. These foundational elements set the stage for more advanced components of knowledge engineering.
In upcoming articles, we’ll explore other crucial aspects of knowledge engineering, including:
- Retrieval strategies
- Integration patterns with LLMs
- Data governance and compliance
- Observability and monitoring
Stay tuned as we continue to dissect the components that make modern knowledge engineering both challenging and exciting.
If you find this blog helpful, send me claps and comment below. Your feedback is much appreciated!